
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- deep daiv. week4 팀활동과제
- deep daiv. 2주차 팀 활동 과제
- deep daiv. project_paper
- deep daiv. week3 팀활동과제
- deep daiv. WIL
- Today
- Total
OK ROCK
[NLP] BART : Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension 본문
[NLP] BART : Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension
서졍 2024. 3. 10. 20:15Abstract
- BART : Bidirectional Auto-Regressive Transformer
- seq2seq모델의 사전학습 태스크에 쓰이는 노이즈 제거 오토인코더 (denoising autoencoder)
- noise가 첨가된 텍스트로 , 원래의 텍스트를 복원하는 것을 학습한다.
- BERT와 GPT를 하나로 합친 형태로, 기존 Seq2seq 트랜스포머 모델을 새로운 pre-training objective을 통해 학습하여 하나로 합친 모델

Facebook 에서 개발한 BART.(바트 심슨)
Introduction
Self-supervised learning(자기지도학습)은 NLP에서 주목할만한 성과를 보여주고 있음
- MAE(Masked Auto-Encoder)는 문장 내에서 존재하는 단어를 마스킹하여 가려진 텍스트를 다시 재복원(reconstruction)하는 역할의 Denoising Autoencoder가 가장 성공적인 접근 사례이다.
(cf ) MAE 정리 :
최근 BERT(Bidirectional Encoder Representation Transformer) 이후의 연구에서는 마스킹 토큰의 분포를 늘린다던지, 마스킹 토큰이 예측되는 순서를 알아보는 등의 분포를 변형하여 훈련하는 방법을 다루었지만, 이런 방법론들은 본질적으로 Span prediction, Generation에서만 잘 작동하는 정형적인 방법이고, 더 다양한 모든 종류의 태스크에 적용할 수 없다는 것이 문제점이다.
그 이유는, BERT는 일단 이름에서 알 수 있듯이 Encoder이기 때문에 Generation task에 쓰일 수 없고,
GPT(Generative Pretrained Transformer)는 Decoder만 존재하기 때문에 bi-directional(양방향의) 문맥 정보를 반영할 수 없다.
아래의 간단하게 표현한 비교 그림을 보면 이해가 쉽다.

반면 BART는 Bidirenctional + Auto-Regressive Transformer를 합친 모델이고, 많은 종류의 downstream task에 잘 적용된다.
BART의 사전 학습의 2단계는 다음과 같다.
- 텍스트가 임의의 Nosing function을 통해 오염된다.
- Seq2Seq모델은 원래의 텍스트를 복원하기 위해 학습한다.
BART의 장점은 Noising의 유연성이다. 임의적인 어떠한 변형을 주더라도, 기존 텍스트에 바로 노이즈를 첨가할 수 있으며 심지어 input길이도 변형 가능하다.
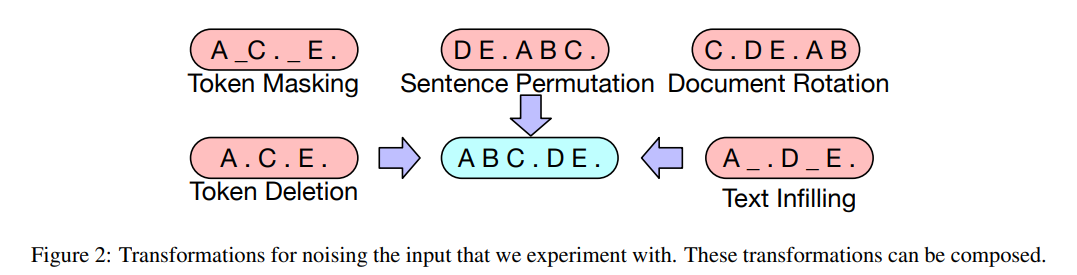
여러 nosing방법들을 실험해봤는데, 최고 성능을 보였던 것은 기존의 문장 순서를 랜덤하게 섞고(Random Shuffling), 임의의 길이를 갖는(0 포함) 텍스트를 단일 마스킹 토큰으로 처리하는 방법이였다.
이것은 BERT의 단어 mask와 그 다음 예측을 일반화한 것으로, 전체적인 문장 길이를 모델이 학습하고 변형되는 nosie input에 더 집중하는 효과를 갖고 있다.
BART는 Generation에 사전학습되었을때 특히나 효율적이다. SQuAD와 GLUE에서 비슷한 수준으로 학습을 진행했을때, 다른 모델인 RoBERTa의 성능과 비슷했고, QA(Question Answering), summarization, abstractive diaglogue등의 다양한 태스크에서 sota성능을 달성하였다.
Model
BART는 노이즈에 방해받은 문서를 원래의 문서(document)로 복원 매핑을 하는 denoising autoencoder이다.
bidirectional 인코더와 left-to-right 자기회귀 디코더로 구성된 seq2seq 모델로 구현될 수 있다.
사전학습에서 NLL(Negative log-likelihood)방법으로 최적화한다.
2.1. Architecture
표준적인 seq2seq Transformer 구조를 따른다. 대신 GPT처럼 ReLU 활성화함수를 정규분포(0,0.02)를 따르는 GeLU함수로 대체하였다.
Base 모델에서 Encoder와 Decoder에 각각 6개의 레이어를 사용했고, Large 모델에서는 12개 레이어로 확대된다.
아키텍처 자체는 BERT와 유사하지만 다음과 같은 차이점이 있다.
- Decoder의 각 layer는 추가적으로 cross-attention을 Encoder에서 마지막 은닉층으로부터 수행한다.
- BERT는 추가적인 feed-forward 네트워크를 단어 예측 이전에 사용하지만, BART는 이런 네트워크가 필요없다.
- 총계적으로, 같은 사이즈의 BART는 10%의 더 많은 파라미터를 갖고 있다.
2.2. Pre-Training BART
Reconstruction loss : (디코더의 출력과 원래 문서간의 Cross Entropy) 를 최적화하면서 denoising 을 학습한다.
기존에 존재하는 denoising autoencoder와 다르게, BART는 어떤 종류의 Nosing function이든 모두 사용할 수 있다는 것이다.(극단적으로는 모든 원천이 없어져도, BART는 일반 언어 모델과 동일하다고 한다)
기존에 있던 변형방법(노이징 방법)에 추가적으로 새로운 변형을 아래와 같이 여러가지 실험했다.
- Token Masking - BERT와 마찬가지로 랜덤하게 토큰을 뽑아 샘플링하고 [MASK] token으로 대체한다.
- Token Deletion - 랜덤한 input의 토큰들은 삭제된다. Token making과는 대조적으로, 없어질 토큰(missing token)의 위치를 무조건 결정해야 한다.(?)
- Text Infilling - 많은 수의 텍스트 span이 샘플되고?, 그 길이는 포아송 분포로부터 뽑혀진다.(람다 = 3) 각각의 span은 단일 [MASK]토큰으로 대체된다. 0-길이의 span은 마스크 토큰의 삽입 내지 추가로 간주된다. 모델에게 얼마나 많은 토큰들이 span으로부터 없어졌는지를 알려주는 역할이다.
- Sentence Permutation -문장을 임의의 랜덤한 순서로 섞는 것
- Document Rotation - 랜덤한 균등분포로부터 토큰을 뽑고, 문서를 그 토큰에서부터 시작되게 rotation시킨다. 이러한 태스크는 모델에게 문서의 어떤 지점에서 시작하는지를 확인하는 작업을 학습한다.
3. Fine-Tuning BART ⭐
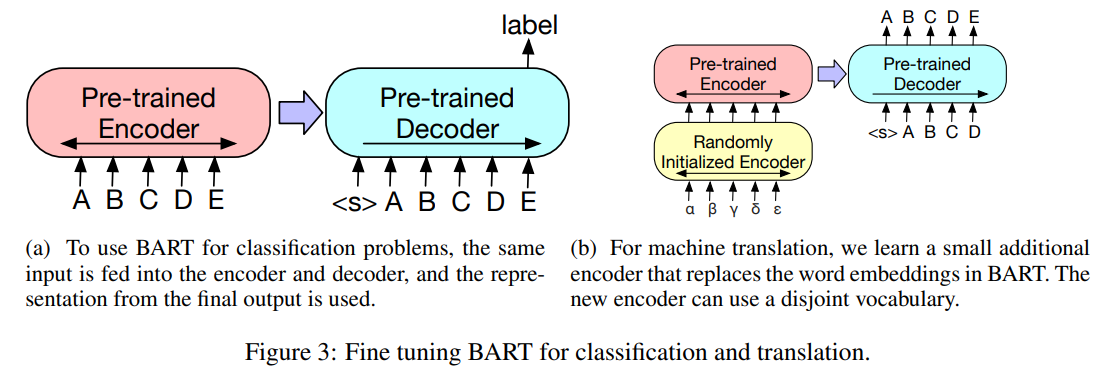
3.1. Sequence Classification Tasks
Encoder와 Decoder에게 같은 input을 먹여준다. 그리고 디코더에서의 마지막 hidden state 토큰을 새로운 multi-class의 선형 분류기에 넣어준다.
이러한 접근은 BERT에서 사용한 <CLS>토큰(classification token)과 유사한 역할을 수행한다.
3.2. Token Classification Tasks
SQuAD 데이터셋에서 답변의 끝지점을 알아보는 방식의 token classification 태스크를 진행하는 과정에서, 본 논문에서는 Encoder와 Decoder에게 완전한 문서(complete document)를 먹여준 후에 Decoder의 hidden state 최상단 부분을 각각의 단어 표현으로서 사용한다. 이러한 표현이 토큰을 분류하는데에 사용된다.
3.3. Sequence Generation Tasks
BART자체가 decoder이기 때문에 직접적으로 추상적인 question-answering이나 summarization작업과 같은 생성 태스크들에 다양하게 fine-tuned될 수 있다.
앞서 언급한 QA나 요약태스크 둘 다에서 input을 복제한 것에서 정보를 뽑아 사용한다. 인코더에는 input sequence와 동일한 것을 넣고, 디코더는 출력을 자기회귀적으로 생성시킨다.
3.4. Machine Translation
영어로 번역하는 기계번역 작업에서도 fine-tuning을 수행할 수 있다.
이전까지의 논문들에서는 전체 모델을 machine translation에서 pretrained된 인코더들을 통합하여 구성함으로서 성능을 향상시켰지만, 이것은 decoder에 pretrained된 언어 모델들에게서는 제한이 있다는 특징이 있었다.
BART는 전체의 모델(인코더와 디코더 모두)을 기계번역 태스크에 pretrained된 하나의 single decoder로 사용하는 것이 가능하다는 것을 보여주었다. bitext로부터 학습시킨 새로운 인코더 파라미터를 추가하는 방법으로 해결하였다.
조금 더 정밀하게 설명하면, 인코더의 embedding layer를 새롭게 초기화시킨 인코더로 교체한다. 이 모델은 end-to-end로 학습되며, 다른 외국어로부터 영어를 매핑하여 모델이 denoise할 수 있게 해준다.
인코더를 다음의 2가지 스텝으로 훈련시킨다.
첫 번째 스텝에서 BART의 대부분의 파라미터들을 우선 freeze시키고, 랜덤으로 초기화된 source encoder, BART자체의 positional embedding, 그리고 인코더의 첫번째 레이어에서의 self-attention input projection matrix 이 세가지를 학습한다.
두 번째 스텝에서는 모든 모델의 파라미터를 작은 수의 iteration만으로 학습하는 것이다.
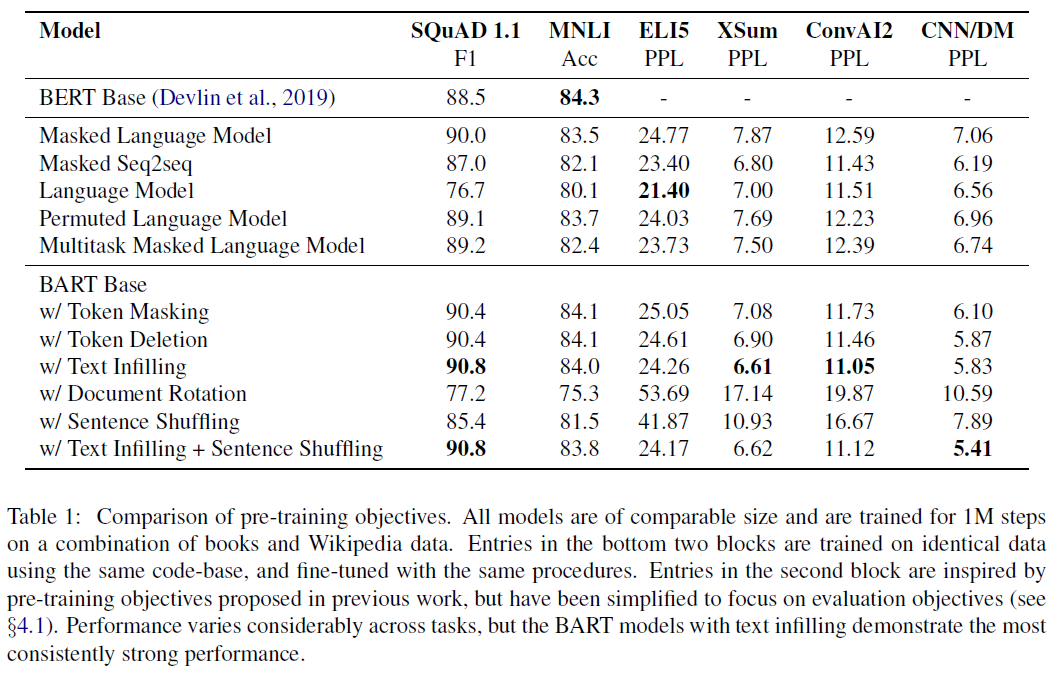
Results
(Experiments ~ Conclusion etc 생략)
👍 다음주 금(3/15)까지 할 것
- Ko-BART 코드 공부하기 :GitHub - SKT-AI/KoBART: Korean BART
GitHub - SKT-AI/KoBART: Korean BART
Korean BART. Contribute to SKT-AI/KoBART development by creating an account on GitHub.
github.com
References
'대외활동 > Deep daiv. project' 카테고리의 다른 글
| [ASR] 한국어 Speech-To-Text, KO-Speech (0) | 2024.03.24 |
|---|
