
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- deep daiv. project_paper
- deep daiv. week3 팀활동과제
- deep daiv. week4 팀활동과제
- deep daiv. 2주차 팀 활동 과제
- deep daiv. WIL
- Today
- Total
OK ROCK
[Audio]SpecAugment : A Simple Data Augmentation Method for Automatic Speech Recognition 본문
[Audio]SpecAugment : A Simple Data Augmentation Method for Automatic Speech Recognition
서졍 2024. 2. 16. 22:510. Abstract
- 음성 인식에 사용되는 간단한 데이터 증강 기법, SpecAugment를 소개
- 오디오에서 뽑은 feature vector를 input으로 Time warping, Frequency masking, Time masking 3가지 방법으로 증강을 적용
- LAS(Listen, Attend and Spell) 네트워크 모델에 end-to-end 기법으로 음성인식 분야에 SpecAugment를 적용했더니, sota성능 달성
1. Introduction
- 딥러닝은 자동화 음성인식 분야(ASR, Automatic Speech Recognition)에 성공적으로 적용됨
- 지금까지의 음성 인식 연구는 대부분 모델 아키텍처 자체에 초점이 맞추어져 진행되어 왔으나, 이 모델들은 쉽게 오버피팅이 발생하고 많은 양의 학습 데이터가 요구되는 경향성을 보임
- SpecAugment는 raw audio 그 자체보다, input의 음성 데이터의 log mel spectrogram에 방법을 적용하는 차이점이 있다. 이렇게 함으로써 더 간단하고 계산적으로 가벼
- 본 논문은 기존의 Augmentation기법들이 어떤 방식으로 적용되었는지 아래와 같이 설명을 간단하게 함
[1] Noise Injection
: 기존 데이터에 임의의 난수를 더해서 잡음을 추가하는 방법
[2] Shifting Time
: 임의의 값만큼 음성 신호를 time domain에서 좌,우로 shift(이동)하고, 나머지 공간은 0으로 채우는 방법
[3] Changing Pitch
: 기존 음성 신호의 Pitch(음의 높이)를 랜덤하게 변경하는 방법
[4] Changing Speed
: 기존 음성 신호의 속도를 변경하는 방법
2. Augmentaton Policy
그렇다면 이제 이 논문에서 제안하는 SpecAugment에 대해서 알아보도록 하겠다.
[1] Time Warping

기본적으로 tensorflow 라이브러리의 sparse_image_warp 함수를 이용하여 구현할 수 있다.
time step에 대해 log mel spectrogram이 들어오면, 이것을 time domain이 수평 축으로, frequency가 수직 축으로 대응되는 이미지로 해석할 수 있다. 이를 Computer viion에서 사용하는 Image Warping의 방법을 응용시켜 같은 원리로 이해할 수 있다. 즉 축의 중심으로 빨간색 원과 같이 이동시켜 Time warp을 적용한다.
즉 임의의 점이 선택되고, 해당 선을 따라서 0부터 시간 왜곡 매개변수 W까지의 균일 분포에서 선택한 거리 w로 왼쪽 또는 오른쪽으로 warping시킨다.
[2] Frequency Masking
Log Mel Spectrgram의 frequency축을 따라 일정 영역을 0으로 위의 그림과 같이 마스킹하는 방법이다.
def freq_masking(feat, F = 20, freq_mask_num = 2):
feat_size = feat.size(1)
seq_len = feat.size(0)
# freq mask
for _ in range(freq_mask_num):
f = np.random.uniform(low=0.0, high=F)
f = int(f)
f0 = random.randint(0, feat_size - f)
feat[:, f0 : f0 + f] = 0
return feat
code 내부를 보면, frequency channel의 [f0,f0+f]가 0으로 마스킹 되는 것을 확인할 수 있다.
이때, f0은 [0,v−f)에서 선택되고 여기서 v는 frequency channel의 갯수이다.(주로 80차원 mel spectrogram이 사용되기 떄문에 v는 80임)
[3] Time Masking
frequency 축이 아닌, Time domain에서 위의 [2] 방법과 같이 0으로 마스킹하는 방법이다.
def time_masking(feat, T = 70, time_mask_num = 2):
feat_size = feat.size(1)
seq_len = feat.size(0)
# time mask
for _ in range(time_mask_num):
t = np.random.uniform(low=0.0, high=T)
t = int(t)
t0 = random.randint(0, seq_len - t)
feat[t0 : t0 + t, :] = 0
return feat
연속 time step $$가 마스킹되고, t는 0에서 시간 마스크 매개 변수 T까지의 균일한 분포에서 선택된다.
t0은 $에서 선택됨
이때, Frequency Masking과 Time Masking 적용 시 주의점은 마스킹하는 영역의 범위를 적당하게 지정해주어야 한다는 것이다.
- 너무 많이 / 적게 적용한다면 Augmentation의 효과가 덜하거나 심한 경우 Noise가 될 수 있음


3. Model
LAS(Listen, Attend and Spell) Model을 사용하여 실험을 진행하였다.
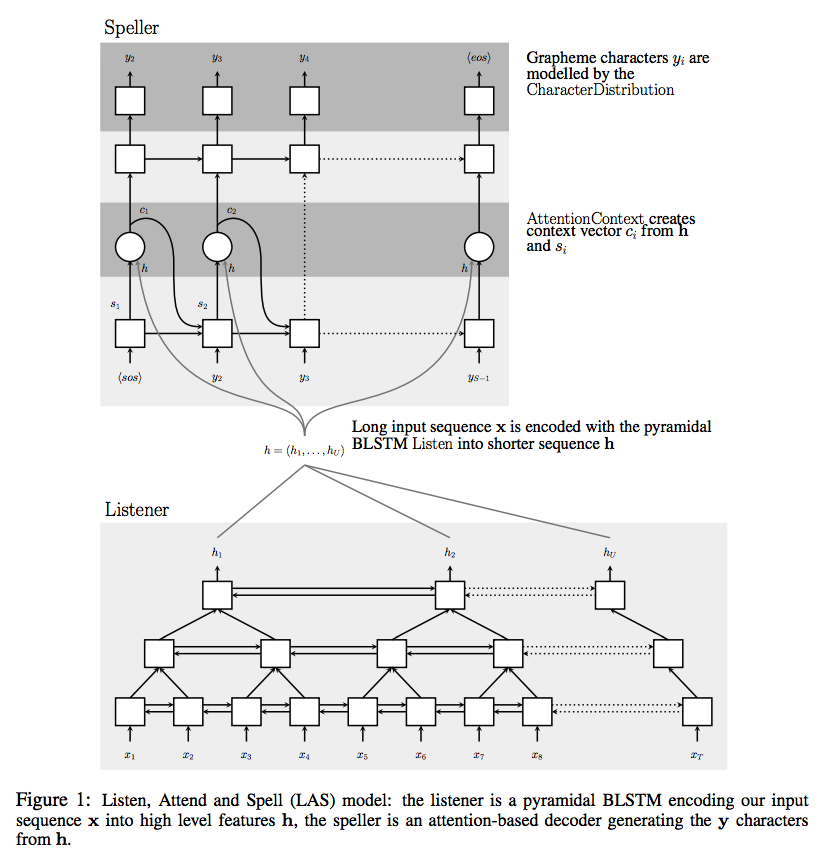
- log mel spectrogram을 입력으로 받아, 2-Layer의 maxpooling이 적용된 CNN을 거침.(Stride = 2)
- CNN을 거쳐서 나온 output을 Encoder의 Stacked Bi-LSTM의 입력으로 넣음.
- Encoder에서 encoding 과정을 거친 output을 attention 기반의 Deocoder에 넣어 예측 시퀀스를 뽑아냄.(디코더 레이어 사이즈 = 2)
4. Experimental setup and Results
- 최대 학습률을 으로, batch_size를 512로, 32 개의 Google Cloud TPU를 사용하여 학습
- Encoder layer에서 stride size가 2 인 32 개 채널이 있는 3x3 컨볼 루션의 2 개 layer가 포함되어, 총 시간 감소 계수인 r factor를 4로 설정
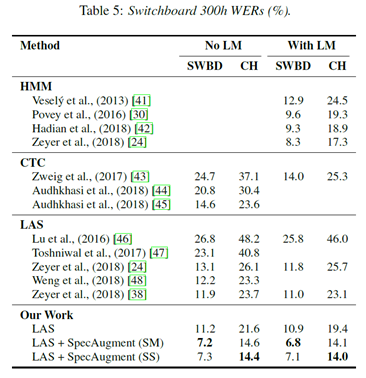
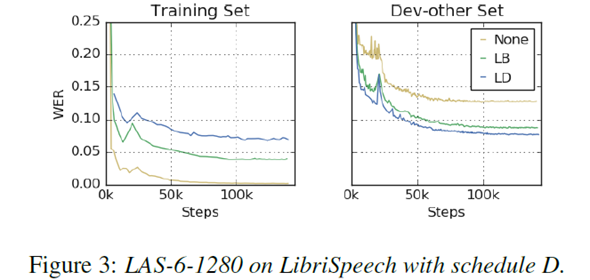
cf) Label Smoothing
Label smoothing의 효과
- 이 실험에서 사용하면 훈련이 불안정해질 수 있음
- LibriSpeech 학습 시 학습률이 점차 감소할 때, Label smoothing과 augmentation이 함께 적용되면 training이 불안정해짐을 밝힘
- 따라서 LibriSpeech에 대한 학습률의 초기 단계에서만 레이블 스무딩을 사용했다고 함
Reference
[1] Park, Daniel S., et al. "SpecAugment: A Simple Data Augmentation Method for Automatic Speech Recognition}}." Proc. Interspeech 2019 (2019): 2613-2617.
[2] Chan, William, et al. "Listen, attend and spell: A neural network for large vocabulary conversational speech recognition." 2016 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2016.



