
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- deep daiv. week4 팀활동과제
- deep daiv. week3 팀활동과제
- deep daiv. 2주차 팀 활동 과제
- deep daiv. project_paper
- deep daiv. WIL
- Today
- Total
OK ROCK
[Audio] WaveNet: A Generative Model For Raw Audio, Oord et al.(DeepMind), 2016 본문
[Audio] WaveNet: A Generative Model For Raw Audio, Oord et al.(DeepMind), 2016
서졍 2024. 2. 8. 23:210. Abstract
WaveNet
- raw audio waveform을 생성하는 딥러닝기반의 음성 생성 모델
- 확률기반적(probabilistic)이고, 자기회귀적인(autoregressive)인 모델
- TTS(Text to speech)분야에서 인간의 음성과 유사한 더 자연스러운 음성을 생성하여 s-o-t-a 달성
- 음소 인식(phoneme recognition)분야에서도 차별적이고 중요한 성능 달성
1. Introduction
2016년 [V. Oord et al., 2016] 에 발표된 이미지 또는 텍스트의 분포를 결합하여 조건부 확률분포적으로 해석한 모델이 생성분야에서 sota를 달성하였다.
이러한 자기 회귀적인 생성모델에 영감을 받아, WaveNet은 PixelCNN [V. Oord et al., 2016] 모델에 기반을 두어 음성 데이터에 아이디어를 적용한 생성 모델이다. WaveNet으로1초에 최소 16,000 sample을 얻은(Figure1) 매우 높은 해상도의 raw audio waveform을 생성할 수 있다.

중요한 업적은 다음과 같다.
- TTS에서 상대적으로 자연스러운 음성 생성이 가능
- 매우 높은 수용 영역을 보여줄 수 있는, dilated causal convolution에 기반을 둔 새로운 아키텍쳐를 제안
- 발화자(speaker)의 특성에 조건을 둔다면, 단일 모델로 다른 음성을 생성 가능
TTS나 음성 변조(voice conversion) 등의 음성 생성 분야에서 매우 유연하게 사용될 것이라 기대한다.
2. WaveNet (Architecture)
즉각적인 raw audio waveform을 생성하는 새로운 생성모델 구조를 본격적으로 소개하도록 한다.
파형(waveform)을
따라서 각각의 음성 샘플
PixelCNN에서도 이와 비슷하게 각각의 convolution 층들을 stack구조로 쌓음으로써 조건부확률분포를 이용하였다. 이 네트워크에서는 pooling layer가 존재하지 않으며, 모델의 output은 input과 같은 시간 차원을 공유한다.
모델의 출력결과는 softmax layer를 통과한 다음의 파형 인자
2.1. Dilated Causal Convolutions
WaveNet구조의 가장 핵심적인 부분이다.
Causal convolution을 이용함으로써, time step
이미지 데이터에 대해서는 픽셀을 마스킹하는 방식으로 masked convolution을 사용하여 masked tensor를 stack처럼 쌓고, elementwise하게 곱함으로써 convolution을 수행하게 된다.
음성데이터와 같은 1-D데이터는 몇 개의 timestep에서의 convolution결과를 위의 figure3의 과정과 같이 단순하게 shifting하는 것으로 구현될 수 있다.
예측은 sequential하게 발생되기 떄문에, 각각의 샘플이 예측된 후 이것들은 다음 샘플을 예측하기 위해 다시 네트워크에 집어넣어져서 fed back되는 특성을 갖고 있다.
causal convolution은 RNN에 비해 학습속도가 굉장히 빠르고 긴 sequence에 대해서도 잘 작동하지만, 학습을 위해 많은 layer가 필요하고 수용 영역(receptive field)를 키우려면 많은 filter가 필요하다는 문제점이 있다.
이 문제점들을 완화하기 위해, 더 나아가 Dilated convolution개념을 결합한다.
위의 그림에서 layer끼리의 shift과정에서 노드의 간격을 dilation이라고 명칭한다. 즉 입력값이 특정 단계를 건너뛰도록 설계함으로써 필터가 길이보다 더 큰 영역에 적용되도록 역할을 수행한다.
이것은 일반적인 convolution보다 더 광범위한 규모에서 효과적으로 작동되며, pooling과 stride개념을 사용하는 이미지에서의 2-d convolution과 유사한 개념이지만, 출력값이 입력값과 같은 차원을 가진다는 점에서 차이점이 있다.
참고로 dilation이 1인 dilated convolution은 일반 Convolution과 같은 결과를 보인다.
2.2. Softmax Distribution
일반적으로 개별 오디오 샘플에 대한 조건부 분포
Raw audio 데이터는 16비트 정수값(하나의 time step당 1)로 저장되기 떄문에 softmax layer는 출력값으로 하나의 time step당 65,536개의 확률값을 필요로 한다.
이러한 계산을 다루기 쉽게 하기 위하여,
수식으로 표현하면 다음과 같다.
수식에서 사용된
이러한 비선형적 계산의 양자화는 일반적인 선형 양자화보다 더 reconstruction을 잘하고, 특히 음성분야에서 원본 오디오와 굉장히 유사하게 재구성한다는 것을 발견했다.
2.3. Gated Activation Units
Gated PixelCNN [V. Oord et al., 2016] 논문에서 사용한 gated activation unit을 똑같이 사용하였다.
$$z = \tanh (W_f,_k*x) \odot \sigma (W_g,_k*x) $$
수식에서 사용된 *는 convolution연산,
2.4. Residual and Skip Connections
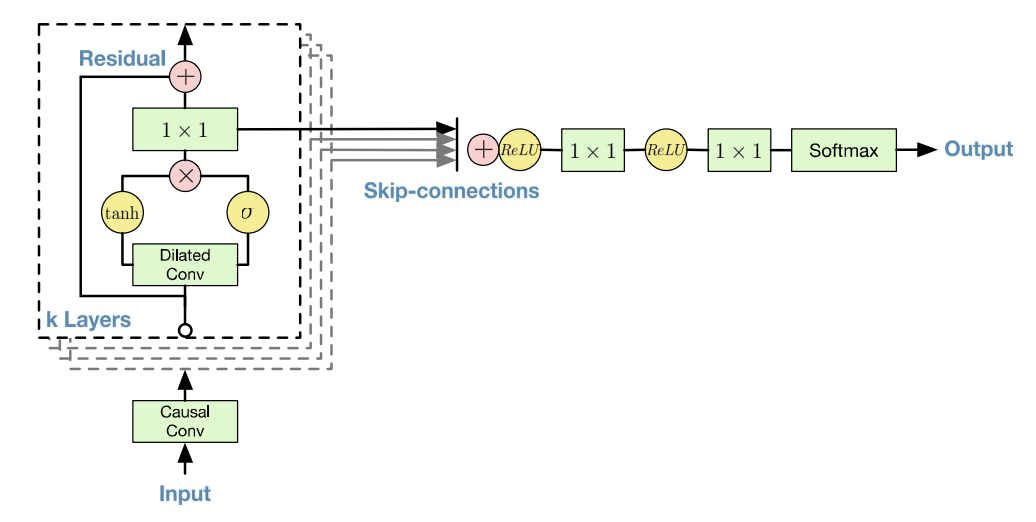
residual connection과 매개변수화된(parameterized) skip connection을 네트워크에 적용하여 학습의 수렴 속도를 높였고, 더 모델을 깊게 쌓을 수 있었다. 전체 모델구조의 개요와 이를 적용한 그림은 위의 Figure 4에서 확인할 수 있다.
2.5. Conditional WaveNets
오디오 input(
이렇게 다른 input 변수(h)를 조절하면서, 요구되어지는 특성에 맞게 결과를 생성해낼 수 있다.
예를 들어, Multi-Speaker setting에서는 그 발화자의 특성이나 독자성(identity)을 추가로 입력할 수 있다.
이와 유사하게 TTS에서는 추가 입력값에 Text에 대한 정보를 넣어주게 된다.
WaveNet에 h와 같은 다른 입력값을 주는 방법으로는 다음의 두 가지 방식이 있다.
1) Global Conditioning
여기서
2) Local Conditioning
이 방식에서는
언어적 정보의 시퀀스를 오디오 신호와 동일한 해상도로 맞춰주는 upsampling을 하기 위해서 transposed convolution을 활용할 수 있으며, 이렇게 upsampling된 새로운 시계열 시퀀스정보
여기서
2.6. Context Stacks
수용 영역을 확장하기 위해 앞의 2.1 dilated convolution 파트에서 방법들을 언급하였다.
추가로, 음성 신호의 긴 부분을 처리할 때 작은 context stack으로 사용하고, 짧은 부분만을 처리하는 더 큰 WaveNet을 부분적으로 분리하여 조절하는 방법이 있다. (3의 실험 결과에서 보이겠지만 약간의 성능 하락이 있었다.)
3. Experiments
Multi-speaker의 음성생성, TTS, 음악 오디오 모델링 이렇게 크게 3가지 문제로 WaveNet의 음성생성 성능을 측정하였다.
추후 정리
Reference



